



Next: French Mobility: an example
Up: Numerical Methods for Estimating
Previous: Numerical Methods for Estimating
Contents
In some historical data sets, certain data may be known to be affected
by external agents such as war, or there may be some other bias or
problem. This provides an incentive for weighting data sets.
This is accomplished by introducing a weight vector of length 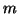
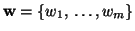 that contains the weight for each data
point
that contains the weight for each data
point 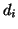 . Weighted least squares is thus denoted
. Weighted least squares is thus denoted
vary
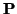
such that
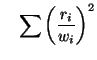
is minimized
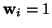 for all
for all 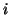 , then we have the same model as before.
, then we have the same model as before.
With historical time-series data, a more accurate analysis may be
achieved by focusing on ``quiet'' periods and excluding unrepresentative
data; for example, an analysis of nuclear testing data might be
improved by excluding data from the years around the signing of the
Nuclear Test Ban Treaty. Exclusion is accomplished by setting
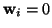 for certain values of . This is sometimes referred to as
``masking'' data, as we are hiding some of the points from the
fitting engine.
for certain values of . This is sometimes referred to as
``masking'' data, as we are hiding some of the points from the
fitting engine.
Loglet Lab accommodates masking of the data. However, it does
not allow use of user-specified weight vectors, though this
functionality could be added in the future.
Next: French Mobility: an example
Up: Numerical Methods for Estimating
Previous: Numerical Methods for Estimating
Contents
Jason Yung
2004-01-28